| Главная » Файлы » Программируем в 1С » 1С Разное |
Скачивать материалы с сайта, могут только зарегистрированные пользователи.
Для регистрации заполните два поля ниже!
Через минуту Вы получите "Гостевой доступ"
| 2014 Сентябрь 06, 10:10 | |
Дисковая подсистема узкое место 1С Предприятия.
Часто «узким» местом в работе с 1С Предприятием является дисковая подсистема. Конечно, это не открытие и многие знают или, по крайней мере, догадываются о существовании такой проблемы, а самые шустрые даже пытаются решить ее покупкой нового HDD или SSD. Суровая реальность в том, что часто такая покупка не принесет ничего больше чем похудание вашего кошелька и разочарования. А все из-за того что человек не понимает как выполняются типы операций ввода-вывода, над какими данными и с какой интенсивностью и прочие технические моменты дисковой подсистемы. Наверняка Вы слышали о блокировках таблиц, которые возникают при интенсивной работе с базой данных большого числа активных пользователей или других операций, что подымают большое количество таблиц. Именно эти блокировки возникают, когда стоят очереди на чтение – запись. Это и есть проблема №1 дисковой подсистемы в 1С. В этой статье хочу разложить по полочкам дисковую подсистему, постараюсь объяснить как можно проще, как это работает. Уверен, что после прочтения этой статьи Вы будете совсем по-другому смотреть на HDD и SSD.
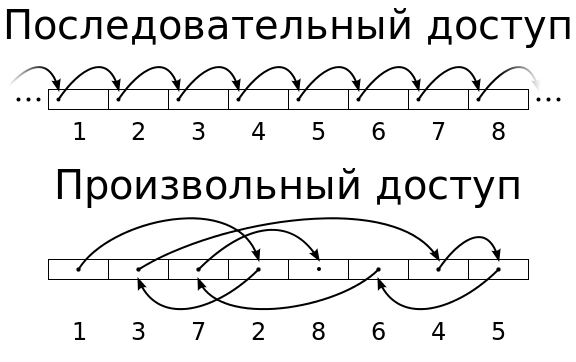
Для работы с таблицами очень важно чтоб количество операций чтения и записи было как можно больше за промежуток времени. Количество этих операций измеряются в IOPS. (количество операций ввода-вывода в секунду). Основными измеряемыми величинами являются операции линейного (последовательного) и произвольного (случайного) доступа. Линейными операциями - называют операции, когда части файлов считываются последовательно, одна за другой, здесь подразумевается передача больших файлов (более 128 К). Произвольные операции - это операции когда данные читаются случайно из разных областей носителя, обычно они ассоциируются с размером блока 4 Кбайт.
Обычно линейные IOPS проще показать в Мбайт/с и Гбит/с, собственно так нам их и показывают. Вот простая формула: IOPS * Размер_блока_в_байтах = Байт_в_секунду. (обычно преобразуется в Мбайт/с – для чего нужно поделить на 1000000, обычно просто убрав последние 6 нулей) Существуют программы способные измерить IOPS. LOmeter – одна из таких программ. (от Intel).
Проводить лично тесты я не стал, так как это успешно сделали авторитетные ресурсы еще до меня. Моя задача в доступной форме объяснить и показать Вам как это работает, используя эти примеры.
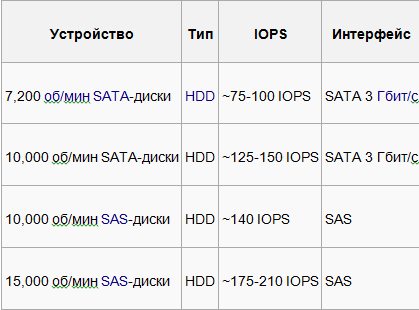
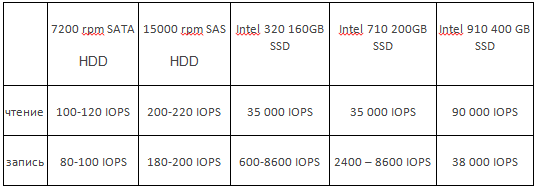
Приблизительные значения IOPS для жестких дисков: Таблица №1. Обычные HDD
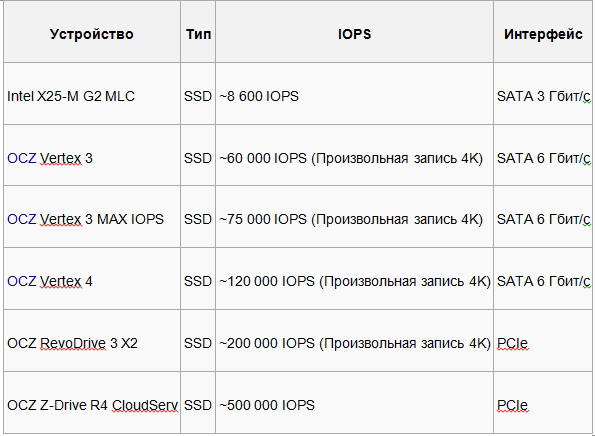
Таблица №2. Приблизительные значения IOPS для SSD (в идеальных условиях и непродолжительное время - при продолжительной случайной нагрузке на запись скорость падает в 2-10 раз по сравнению с заявленными характеристиками)
И так исходя из того что мы видим в таблице №1 и таблице №2 можно сделать вывод Вывод №1 IOPS для всех HDD почти одинаковы, небольшой отрыв видно только у дисков под интерфейсом SAS. Простыми словами гнаться за новыми HDD пока нет особого смысла.
Вывод №2 Существенно эффективны SSD только в «Произвольном доступе»
В остальном эти показатели можно делить на 10, но и в этом случаи SSD остаются быстрее обычных HDD. Почему так SSD быстрее HDD объяснить не сложно. Для жёстких дисков и других электромеханических устройств при произвольном доступе происходит поиск (перемещение головок), на что собственно и идут затраты IOPS. В то время как в SSD и системах хранения, сделанных на их основе, количество IOPS в основном зависит от работы внутреннего микроконтроллера и скорости интерфейса памяти. Что ж мы разобрались в «скоростях» знаем как их рассчитывают.
Теперь посмотрим на таблицы 1С. Материал ниже предоставлен сайтом: http://ko.com.ua/proektirovanie_servera_pod_1s_66779
База объемом 200-300 MB с 3-5 пользователями может генерировать в пиках до 400-600 IOPS. База на 10-15 пользователей и объёмом в 400-800 MB способна выдать 1500-2500 IOPS, База на 40-50 пользователей и объёмом 2-4 GB выдает 5000-7500 IOPS, а базы под 80-100 пользователей легко достигают 12000-18000 IOPS.
На таблице показаны пиковые данные, собственно они нам и интересны, а в обычной работе цифры IOPS будут на 90% меньше. Современные диски в операциях чтения и записи со случайным доступом чтение / запись в одиночку справляются с такими нагрузками:
Хорошо видно, что:
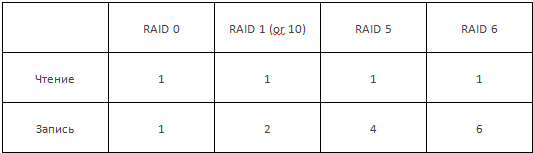
Одиночные диски в серверах БД как правило не используются, только RAID-массивы. Для дальнейшего расчета реальной производительности дисковой подсистемы нужно учесть затраты на запись «штраф». в IOPS, которые несет RAID- массив.
Если собрать 6 дисков в RAID 10, то на каждую запись в 1 IOPS данных будет потрачено 2 IOPS физических дисков, а если в RAID 6 — то 6 IOPS дисков. Таким образом, при расчете нагрузочных возможностей дисковой группы на запись нужно вначале сложить IOPS всех дисков RAID-группы, а затем разделить их на «штраф». Пример 1: 2 HDD SATA 7200 в RAID 1 обеспечат на запись: (100 IOPS *2) / 2 = 100 IOPS. Пример 2: 4 SATA 7200 в RAID 5 обеспечат на запись: (100 IOPS *4) / 4 = 100 IOPS. Пример 3: 4 SATA 7200 в RAID 10 обеспечат на запись: (100 IOPS *4) / 2 = 200 IOPS. Примеры 2 и 3 наглядно демонстрируют, почему для хранения баз данных, у которых типовое распределение чтение/запись составляет 68/32, предпочтителен RAID 10. Из данных трех таблиц понятно, по какой причине производительности типового «джентльменского набора» 2 HDD SATA 7200 в RAID 1 серверу недостаточно: при пиковых нагрузках растет очередь обращений к диску, пользователи ожидают ответа системы, иногда по многу часов. Как увеличить производительность дисковой подсистемы на запись? Наращивают количество дисков в RAID-группе, переходят к дискам с большей скоростью вращения, выбирают уровень RAID c меньшим штрафом на запись. Хорошо помогает кеширование RAID-контроллером с включенным режимом отложенной записи Write back. Данные пишутся не напрямую на диски (как в режиме Write Through), а в кеш контроллера, и только затем, в пакетном режиме и упорядоченном виде — на диски. В зависимости от специфики задачи, производительность записи удается поднять на 30-100%. Под слабо нагруженные или относительно небольшие БД (до 20GB) подойдет недорогой способ «добычи IOPS» — гибридный RAID из SSD/HDD. Большего и не нужно филиальной БД на 3-15 пользователей в распределённой структуре вроде сети кафе или СТО. Для объемных (200GB и более) БД с длинным историческим шлейфом данных, либо для обслуживания нескольких объемных БД эффективным может оказаться SSD-кеширование (технологии LSI CacheCade 2.0 или Adaptec MaxCache 3.0). По опыту эксплуатации таких систем, именно в задачах 1С с их помощью можно относительно недорого и без существенных изменений в инфраструктуре хранения ускорить дисковые операции на 20-50%. Чемпионом по быстродействию в IOPS предсказуемо являются RAID-массивы на серверных SSD — как традиционные, с использованием SAS RAID-контроллера, так и PCIe SSD. Мешают их популярности два ограничителя: технологический (производительность RAID- контроллеров или необходимость радикально ломать структуру хранения) и цена реализации. Отдельно следует сказать о хранении индексных файлов и TempDB. Индексные файлы обновляются очень редко (обычно 1 раз в сутки), зато читаются очень и очень часто (IOPS). Таким данным просто необходимо храниться на SSD, c их показателями по чтению! TempDB, используемые для хранения временных данных, как правило, невелики по объему (1-4-12GB), зато очень требовательны к скорости записи. Индексные и временные файлы объединяет то, что их потеря не приводит к потере реальных данных. А значит, они могут размещаться на отдельном (еще лучше — на двух отдельных томах) SSD. Хотя бы и на бортовом контроллере SATA материнской платы. С точки зрения надежности и быстродействия, под TempDB желательно отдать зеркало (RAID1) из SSD, можно на бортовом контроллере, но с обязательным выключением всех кешей на запись. С этой ролью справятся и десктопные SSD — вроде Intel 520-серии, где аппаратная компрессия данных при записи в TempDB будет как раз уместной. Вынос этих задач с общей системы хранения на выделенную скоростную подсистему положительно сказывается на производительности системы в целом, особенно в моменты пиковых нагрузок. В случаях, когда есть возможность обеспечить максимально быструю реакцию администраторов при сбоях, и когда имеются сложные расчетные задачи (складская или транспортная логистика, производство в УПП, объемные обмены в УРБД), TempDB выносят на RAMDrive. Такое решение позволяет выиграть иногда до 4-12%общей производительности системы. Некоторое неудобство возникает только в случае рестарта сервера: если автоматически RAMDrive не запустится, потребуется вмешательство администратора для ручного старта — иначе станет вся система. Еще один важный компонент — log-файлы. Они имеют неприятную для любой дисковой подсистемы особенность — генерировать почти постоянный поток мелких обращений на запись. Это незаметно при средних нагрузках, но сильно ухудшает быстродействие сервера 1С при пиковых нагрузках. Разумно выносить log-файл (в особенности, log-файл SQL) на отдельный физический том, к которому нет высоких требований по IOPS, и на который будет идти практически линейная запись. Для спокойствия можно создать зеркало из недорогих и объемных SATA/NL SAS (для Full log), либо недорогих десктопных SSD все той же Intel 520-й серии (Simple log, или Full log, с ежедневным его Backup и очисткой). В целом можно сказать, что приход SSD в серверы открыл новые возможности увеличения производительности массовых серверов — за счет многоуровневого хранения данных и разумного конфигурирования дискового ввода/вывода. Дисковая подсистема «идеального сервера под 1С» выглядит так: 1. Таблицы базы данных размещены на RAID 10 (или RAID 1 для малых БД) из надежных серверных SSD с обязательным аппаратным RAID-контроллером. При высоких требованиях по IOPS можно рассмотреть вариант PCIe SSD. Для БД большого объема эффективно SSD-кеширование массивов HDD. Если используемая конфигурация 1С и структура данных не слишком требовательны к IOPS, а количество пользователей невелико — хватит традиционного массива из HDD SAS 15K rpm. 2. Индексные файлы вынесены на быстрый и недорогой одиночный SSD, TempDB — на 1-2 (RAID 1) SSD или RAMDrive. 3. Под log-файлы SQL (а желательно и 1С) отведен выделенный том (одиночный физический диск или RAID-1) на SATA/NL SAS HDD или недорогих SSD, либо логический диск на RAID-массиве, на котором расположена операционная система сервера и пользовательские файлы/папки. 4. Операционная система и пользовательские данные хранятся на RAID 1 из HDD или SSD. Если IT-инфраструктура виртуализирована, крайне желательно, чтобы SQL Server был установлен не как виртуальная машина, а непосредственно на физический сервер, на «голое железо». Цена вопроса — от 15 до 35% производительности дисковой подсистемы (в зависимости от оборудования, драйверов, средств виртуализации и способов подключения тома). В виртуализированной среде SQL-сервера подключение томов с таблицами БД, индексными файлами и TempDB к VM обязательно в монопольном режиме по Direct Access. Теперь как говорится коротко о главном: SSD быстрее HDD особенно в операциях произвольного доступа. Все сегодняшние HDD имеют примерно одинаковую скорость чтения/записи. Узким местом и для HDD, и для SSD является запись. Максимальную производительность в скорости дают SSD с интерфейсом PCIe. RAID – массив снижает производительность HDD. (штраф). В расчете производительности RAID – массивов нужно учесть затраты на запись «штраф» в IOPS. RAID 10 быстрее RAID 5. Производительность дисковой подсистемы можно увеличить путем: А) Нарастить количество дисков в RAID-группе. Б) Переход к дискам с большей скоростью вращения. С) Выбрать уровень RAID c меньшим штрафом на запись. Помогает увеличить производительность кеширование RAID-контроллером с включенным режимом отложенной записи Write back. Индексные файлы следует размещать на отдельных томах. log-файл SQL стоит вынести на отдельный физический том. Малые базы данных хорошо работают в RAID 1. SQL server лучше устанавливать на физический сервер. Если статья Вам понравилась, комментируйте. С уважением, Богдан.
| |
| Просмотров: 8348 | Загрузок: 0 | | |


Выразить благодарность - Поделиться с друзьями!
| Всего комментариев: 0 | |